图像识别是计算机视觉的基石,很多更高级的任务(如检测、分割、跟踪)都建立在识别的基础之上,常用作衡量视觉模型性能的基础。图像识别指的是让计算机理解图像内容,输出结果,目标是让机器“看懂”图像。而深度学习通过模仿人脑的工作原理,让计算机能够从数据中学习。在图像识别任务中,深度学习模型能够自动识别图片中的模式和特征,如边缘、形状和颜色,进而识别出图中的对象。
常见的图像识别任务有以下四大类:
-
图像分类
定义:图像分类是计算机视觉中最基本的任务之一,其目标是根据图像的内容将其归类到预定义的类别中。可简单理解为:输入一张图片 → 输出它属于哪个类别。
例如:在二分类问题中,给定一张人的照片,模型输出“人”;在工业检测中,给定一个零件图像,模型输出“OK / NG”。

-
目标检测
定义:不仅需要识别图像中的对象类别,还需要确定这些对象在图像中的精确位置,通常通过绘制边界框来实现。在自动驾驶、视频监控等应用至关重要。

-
语义分割
定义:语义分割是一种图像分割技术,它旨在为图像中的每个像素分配一个类别标签。和图像分类(对整张图像分类)或目标检测(检测并框出物体)不同,语义分割要对每一个像素进行分类)。
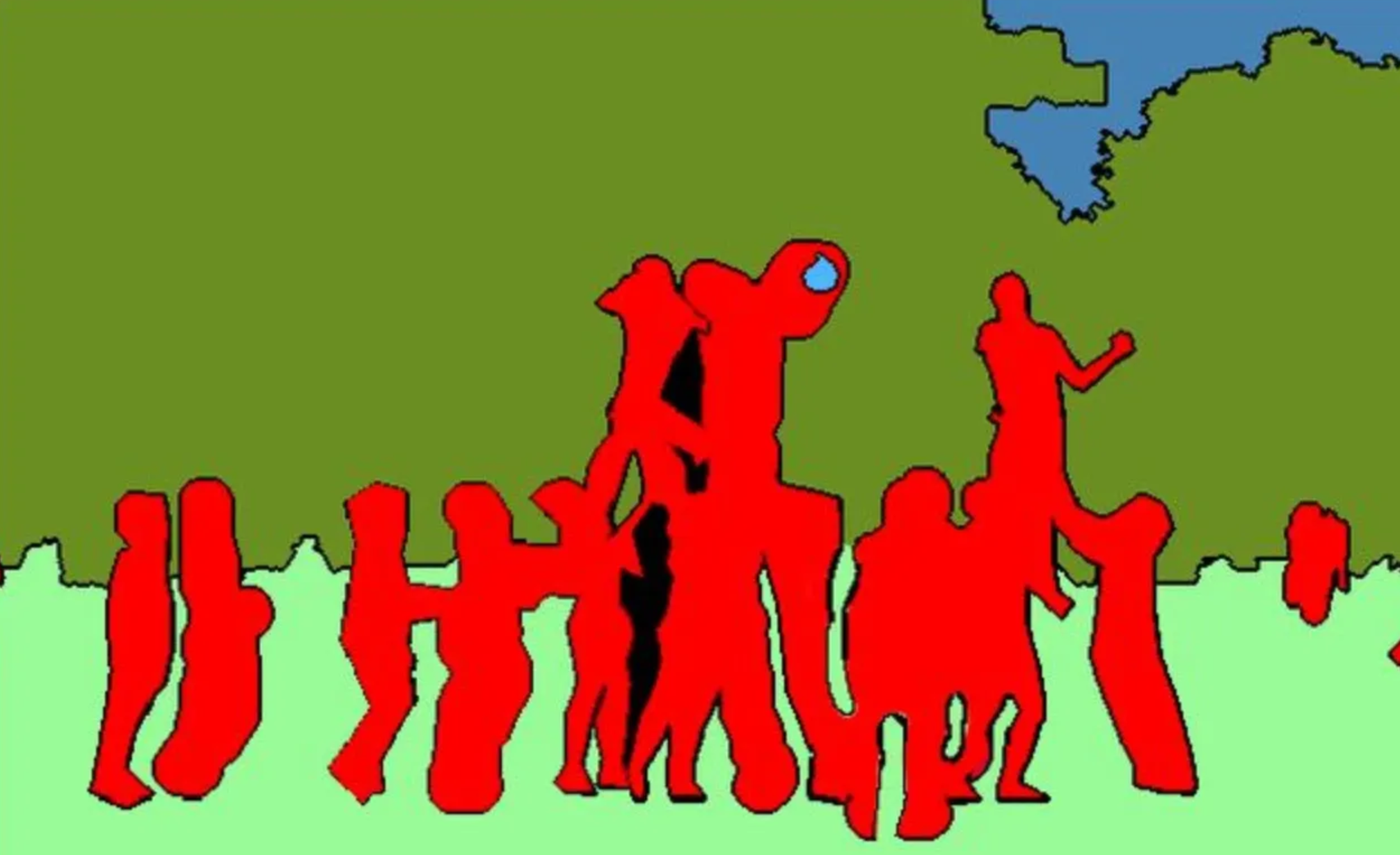
举例:在人群中,可以用像素点来显示出人的位置,会比目标检测更精确;在工业质检中,缺陷检测可以通过语义分割的原理来精确标注裂纹、划痕、异物的区域;
-
实例分割
实例分割是图像分割的一个子集,它不仅要区分图像中的不同对象类别,还要区分属于同一类别的不同实例(即不同的个体)。与图像分割的区别在于,实例分割不仅识别对象类别,还识别不同对象实例之间的差异,为每个对象实例分配一个唯一的标识符。
举例:一张图里有 一群人,语义分割将这这群人的像素标注为“人”,而实例分割不仅标注为“人”,还会区分谁是小红、小明、李华……

深度学习图像分割主要有语义分割、实例分割和全景分割,三者关系也是从易到难。语义分割关注整体的类别分配,识别图像中的每个像素所属的对象类别。而实例分割关注
分割精度指标:
主要用于评估模型在像素级别预测上的好坏。常用的指标和分类/检测有所不同,更关注 像素重叠情况和区域一致性。下面分享工业检测领域中常见的精度指标:
-
交并比 (Intersection over Union, IoU)
交叉比(IoU)是用来衡量预测分割区域与真实分割区域之间重合程度的指标。IoU 越接近 1,说明预测越准确。
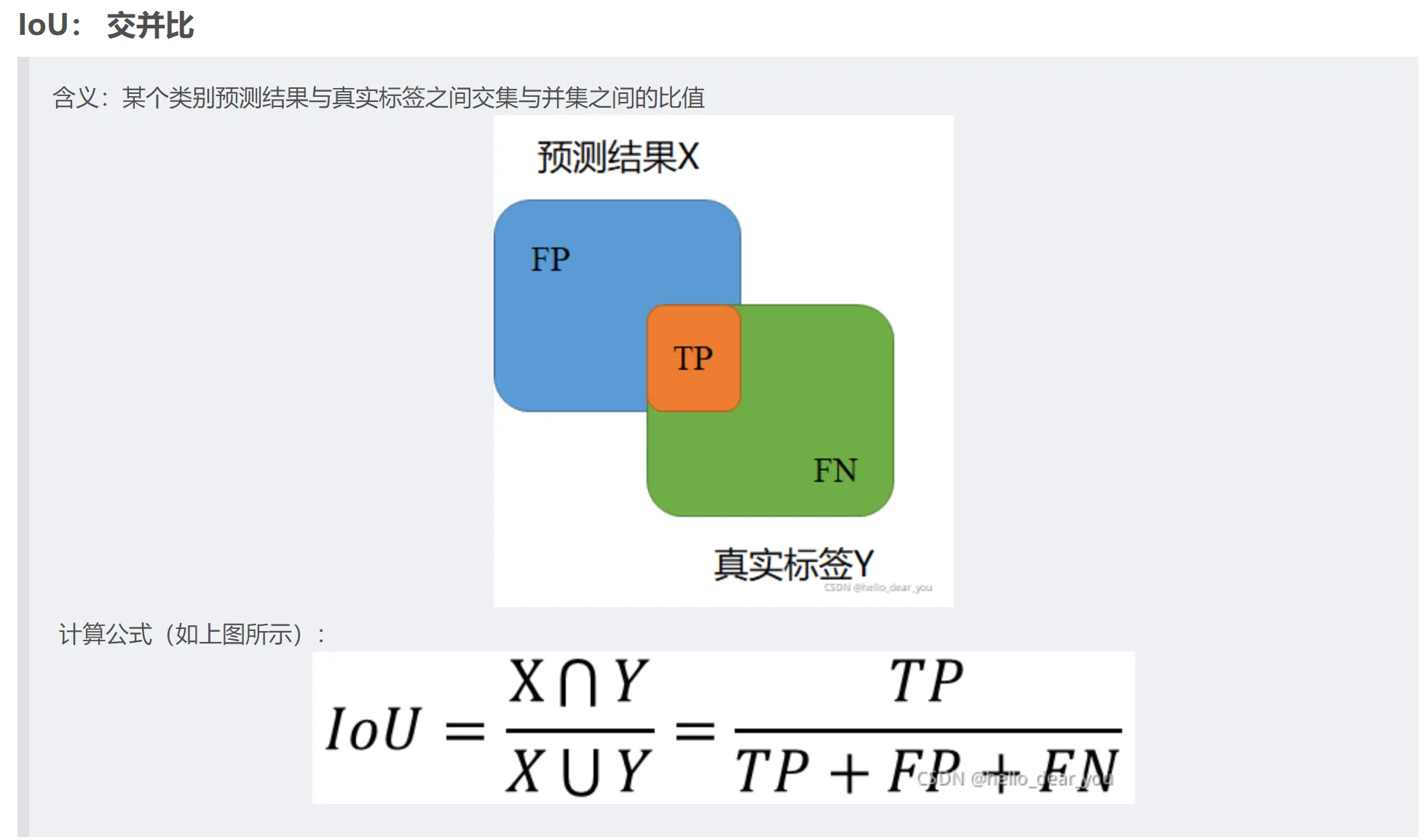
-
准确率 (Pixel Accuracy)
准确率是衡量所有像素中被正确分类的比例。
TP:表示一个样本被预测为正类,并且真实标签为正类
FN:表示一个样本被预测为反例,但是真实标签为正例
FP:表示一个样本被预测为正例,但是真实标签为反例
TN:表示一个样本为预测为反例,并且真实标签为反例
图像识别让机器看懂图像里有什么,而图像分割让机器看懂图像中的每个像素属于什么。二者关系可以理解为:图像识别可以看作是分割的“简化版本”,分割是识别的“精细化版本”。在工业质检中,图像识别 先判断零件合格/不合格;图像分割 则能精确标出缺陷的位置、形状和面积。