在AI视觉检测系统中,算法是“智慧大脑”,而数据则是它的“养分”。对于视觉外观缺陷检测而言,缺陷样本的质量与数量,对AI视觉模型的检测精度和稳定性起决定性作用。可以说没有好的缺陷样本,就没有好的AI视觉检测模型。
一、缺陷样本是什么?
缺陷样本是指在产品中出现的各种异常或不良状态的图像数据,例如:划痕、凹坑、异物、污渍等。这些样本不仅包含缺陷的外观信息,还常常带有缺陷位置、类型、尺寸等标注信息,是AI视觉模型训练不可或缺的核心素材。

二、缺陷样本为何如此重要?
(一)决定模型的“认知边界”
深度学习的本质是通过大量样本学习特征。模型能识别的缺陷类型、特征范围,都来源于训练数据。如果样本不足或不够多样化,模型的“知识库”就会不完整,在实际产线运行过程中容易导致漏误判。
(二)影响检测精度与稳定性
样本分辨率低 → 缺陷细节丢失,边缘识别困难
样本标注不准 → 模型学到错误特征,误判率提升
样本分布不均 → 模型倾向于判定为多数类别(通常是“合格”),漏判风险高
(三)决定模型的泛化能力
生产环境中,缺陷可能因材料批次、设备磨损、工艺调整而呈现不同形态。样本越多样化,模型在新场景下的适应性就越强。
三、缺陷样本不足带来的风险
漏检率高:模型无法识别训练中未见过的缺陷类型
误判率高:正常特征被误判为缺陷
上线不稳定:容易出现实验室效果好,产线表现差的情况
维护成本高:需要频繁收集新样本、重新训练
四、优质缺陷样本的标准
准确标注:缺陷类型、位置、范围标记精确无误
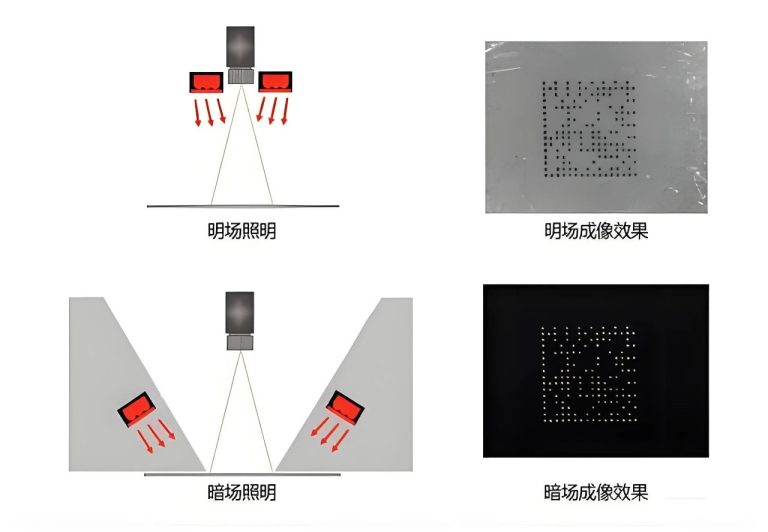
高质量成像:光照均匀、分辨率高、细节清晰
多样性:覆盖不同形态、角度、尺寸、颜色的缺陷
数量充足:各类缺陷样本数量平衡,避免数据偏差
真实场景一致性:采集环境尽量与实际生产一致

结语
从数据到精度,缺陷样本是AI视觉检测系统的生命线。高质量、数量充足且多样化的缺陷样本,不仅能显著提升检测精度,还能让模型具备更强的泛化能力和更具稳定性。对于制造企业来说,投资在缺陷样本采集与管理上,就是在为AI质检系统的成功落地和持续优化打下坚实基础。